
How data leakage happens in machine learning

Photo by Claudio Schwarz on Unsplash
Introduction
Data Leakage is an error caused during the development of a machine learning model. It is one of the most common mistakes made in predictive analytics, and also the least discussed. This type of error significantly impacts the performance of the model in production.
It is also generally referred to as ‘Target Leakage.’ We will use the terms ‘data leakage’ and ‘target leakage’ interchangeably throughout this blog post.
Generally, data leakage occurs in two cases:
-
When the training dataset contains features that give away information about the target feature, this is specifically referred to as Target Leakage.
-
When the information is accidentally shared between the training and test datasets.
Basically, when the training dataset contains information that is not supposed to be a part of it and results in a model with over-optimistic predictions when evaluated on the test data, Target Leakage or Data Leakage is said to have occurred.
Note: The target feature is the feature that we want to predict using the ML model.
Now, why is this a problem?
It is a serious problem because it affects the performance of the model and can go easily undetected until the model is productionized. It only comes to the surface when the model is making predictions on the new data.
A good ML model is a model which can provide accurate predictions on data it has never seen before; this is referred to as ‘generalization’ in machine learning.
To evaluate the model’s performance before deployment, it is tested on the test dataset. This is expected to imitate the performance of the model in the production environment. The best performing model with high scores on metrics like precision and accuracy is selected and used as a point of reference for future model predictions on the new unseen data.
Models with target leakage perform exceedingly well on the test data, as training on data with target leakage produces an over-fitted model but fails to deliver the same performance in production when faced with new unseen data.
Once a model is trained on data with target leakage, it is extremely difficult to eliminate its effects on the predictions. Since it can be detected only in production, it becomes a very expensive mistake to rectify, both with respect to time and money.
Note: Over-fitting occurs when the model learns even from the slightest nuances of the training dataset, like the noise and irrelevant data. It becomes too specific and loses its capacity to generalize on the new unseen data. An over-fitted model has high variance and low bias.
How is data leakage induced?
There are two instances where data leakage is most likely to occur:
- Firstly, during the data collection phase. It is crucial to consider the timeline while selecting relevant features for the specified problem, I.e., the time at which a particular feature was recorded.
The training dataset should contain features that occur before the target feature, which is our prediction point. The features which are generated after the target feature tend to carry information about the target feature. Thus, when these features are included in the training dataset, they leak information about the target feature, and target leakage is induced in the model.
While a model with target or data leakage will achieve unexplainably high accuracy scores with training and test data, it will fail to deliver the same performance when treated with new unseen data. Because the leaky features on which the model was trained will not be available at the time of prediction because, in actuality, they can only be generated after the target feature.
For example, we are building a model to predict if a customer will return the 2nd time to buy a product on an e-commerce platform, and our training dataset includes features like invoice number or product details of their 2nd time purchase. Target leakage is induced.
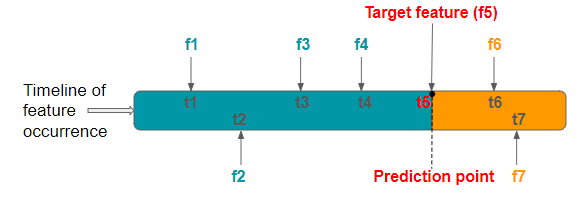
From the above figure, we can spot the leaky features f6 and f7 because they occur after the target feature.
- Secondly, data leakage occurs during the data preparation phase. The whole point of using the test data is to understand how our model will perform in production. But when the integrity of this test data is tainted, this method of evaluation serves no good purpose.
Typically, to evaluate the performance of the machine learning model, we use the technique of cross-validation, where a portion of the dataset is kept aside as test data to test the model performance. When we clean or preprocess data like imputing missing values, removing outliers, or normalizing the entire dataset before the train-test split, we mistakenly induce the error of data leakage.
For example, if we carry out normalization on the entire dataset and then split our data into train and test sets, we leak information about the distribution of the test data into the training data. Likewise, suppose we impute missing values of a particular column with the mean of it before splitting the dataset. In that case, we are introducing information about the test data into the training data, consequently producing an over-fitted model when evaluated on the test data.
How to prevent data leakage?
We need to be careful about a few things while building our machine learning model to avoid data leakage.
- When collecting data, pay attention to the timeline of the occurrence of features. Features occurring after the prediction point are leaky and should be removed.
- The data should be preprocessed after the train-test split. Even in k-fold cross validation, subsets of data should be individually preprocessed. The use of pipelines effectively addresses this issue.
- When dealing with time series data, random splitting of the dataset should be avoided. Train-test split should be carried out by sorting the Date/Time feature.
Conclusion
In this blog post, we addressed the issue of data leakage and how it is induced and discussed a few ways to prevent it. Data leakage is not a widely discussed topic in data science, while it should be as it is one of the most commonly committed mistakes, though inadvertently. One needs to be careful about data leakage when building machine learning models, as it is challenging and expensive to rectify.